随着ChatGPT和GPT4.0的相继问世,拉开了大语言模型和生成式AI产业蓬勃发展的序幕。国内外各大企业和科研机构对ChatGPT的持续跟进,加速推进大语言模型的研发和产品化。
目前市面上出现了诸多类ChatGPT大模型,功能层面也从通用领域扩展到垂直应用领域。例如,百度推出的“文心一言”,腾讯的“混元”,阿里的“通义千言”,360、华为、商汤、京东、科大讯飞(002230)、字节跳动等巨头企业也动作频频,形成了全新的产业格局。
ChatGPT大模型背后是人工智能算法、算力和数据的再一次融合升级。简单来说,应用要高效运行起来,就需要强大算力的支持,而要让应用背后的算法更为聪明,则离不开高质量数据资源。
而摆在“中国ChatGPT”面前的问题,首当其中就是中文语料库的不足。当前GPT大模型主流数据集和评估基准多以英文为主,缺少中文特点、文化,难以满足关键行业应用选型和优化的实际需求,这就会造成所训练的模型对于中英文问题的回答质量并不一致。
以最流行的Common Crawl数据集为例,中文数据占比仅有4.8%。此外,一些对模型能力提升巨大的语料里面,中文占比甚至会更低,例如在源代码的备注里面,英文语料占比高达90%,在专业科研论文审稿意见里,英文占比95%。
因此,“中国版ChatGPT”如果要把中文回答做好,就需要大量高质量的中文语料。基于此,标贝科技启动了大模型技术的非平衡专业语料的构建工作,将于近期陆续推出一系列高质量的数据集,持续解决多领域的GPT大模型非平衡语料问题。
标贝非平衡专业语料库
标贝科技的非平衡专业语料库是基于多年累积的专业数据增强技术和经验,针对优质中文数据资源稀缺的领域、话题和人机交互方式等方面,补全当前开源基础数据的偏差或失衡,构造的一系列增强语料库,来提高中文GPT类模型的泛化能力和鲁棒性。
以标贝科技第一批专业语料――编程辅助数据集为例。现有的公开数据中可以获得的高质量的带有中文注释的代码数据极少,预训练的基础语言模型可能无法在稀缺的中文描述、源代码实现的关联中学习到高级别的代码逻辑。所以目前公开的大多数中文类GPT模型都无法满足高性能的编程请求。
针对这个场景,标贝科技发布了高质量的中文注释代码数据集。该数据集是一个大体量的开放代码学习的数据集,从真实的Github开源项目中收集而来,超过百亿字符,包括高质量代码的中文注释内容以及对应的原始编码,可以用于继续微调(Further pretraining)大型语言模型,以辅助计算机编程和相关教学任务。
标贝科技编程辅助数据集样例
C源代码:左侧为原始代码数据,右侧为增强后的带有中文注释的代码数据
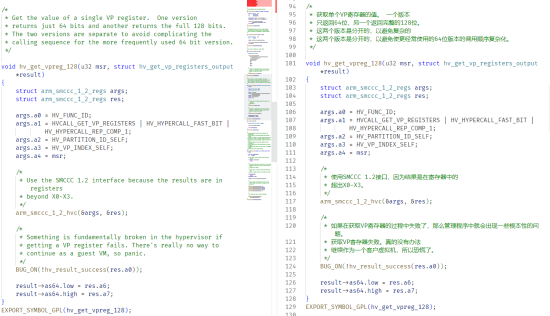
python源代码:左侧为原始代码数据,右侧为增强后的带有中文注释的代码数据

标贝科技编程辅助数据集特点
(1)数据集包含多种类型的代码和文本,包括真实的开源项目、常见的框架、语言等。
(2)数据集由开源社区作者或知名公司提供,具有广泛的功能实现和编程范式。
(3)数据集包含各种复杂度和难度等级的代码,以支持不同层次的用户进行训练。
标贝科技致力于为大语言模型提供终身学习语料
ChatGPT的大规模语言模型浪潮兴起伊始,对数据也提出了全新的要求。如何为大语言模型提供最新的、多样化高质量语料,成为行业面临的共同挑战。
作为行业领先的AI数据解决方案提供商,标贝科技坚持数据服务的创新,积极探索如何满足大规模预训练语言模型的需求,增加数据使用的价值。在对话大模型优化数据设计方案上,标贝科技不仅提供最基本的数据采集和清洗技术服务,还拥有一系列高效处理数据、优化模型的技术能力,持续推动以GPT为代表的大模型技术及应用的创新引领。
接下来,标贝科技还将逐步推出专业审稿意见数据、中文推理链数据、中文视频的VQA数据等多个专业领域的数据语料。同时,我们还可以根据垂直领域需求,提供相应的语料定制服务。欢迎对以上数据集感兴趣的行业伙伴联系我们。
(免责声明:此文内容为广告,相关素材由广告主提供,广告主对本广告内容的真实性负责。本网发布目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责,请自行核实相关内容。广告内容仅供读者参考。)
未经允许不得转载!作者:有问题工单联系,转载或复制请以超链接形式并注明出处哎呦哇啦-Ouch! Wow!。
原文地址:https://www.au28.cn/post/13852.html发布于:2023-05-18



